# Overview
# Why NADA?
The volume and the diversity of socio-economic data available to researchers and analysts have increased considerably over the past decade. But the dissemination of these resources is highly fragmented, and many datasets remain poorly documented. Finding, accessing, and using the most relevant data can be challenging. The production of rich and structured metadata, and their publishing in catalogs with appropriate search features, can significantly improve access and use of data.
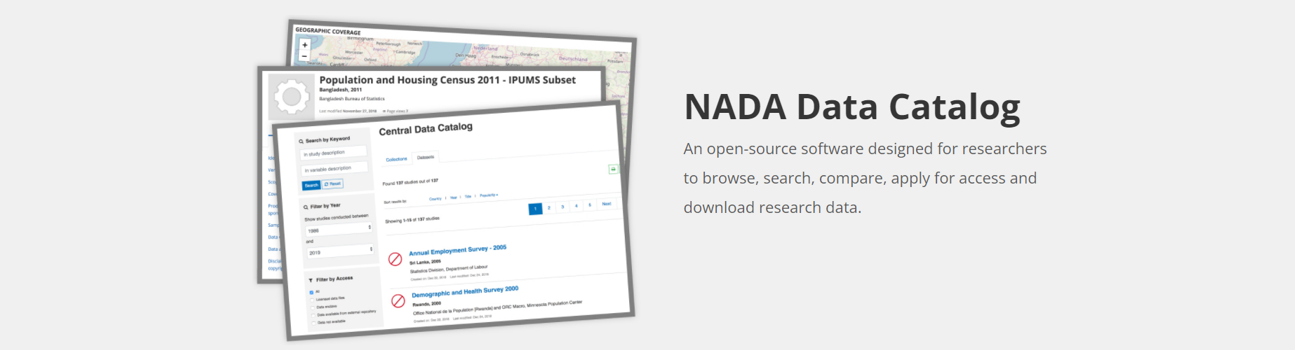
NADA is an open-source web-based data cataloging application. It is used to create portals that allow users to browse, search, compare, apply for access, and download relevant data. It was originally developed to support the establishment of NAtional Data Archives, exclusively covering microdata. It has since then been extended to cover other types of data used for quantitative analysis of social and economic issues. NADA is intended to make such data more usable, more discoverable, and more accessible.
Making data usable implies that comprehensive and detailed metadata are provided to the users in formats convenient to them.
Making data discoverable means that the metadata are published in on-line data catalogs with search engines optimized for discoverability and visibility.
Making data accessible means that the data are made accessible for download in the easiest possible manner, but in compliance with legal, ethical or other legitimate constraints.
# For what data?
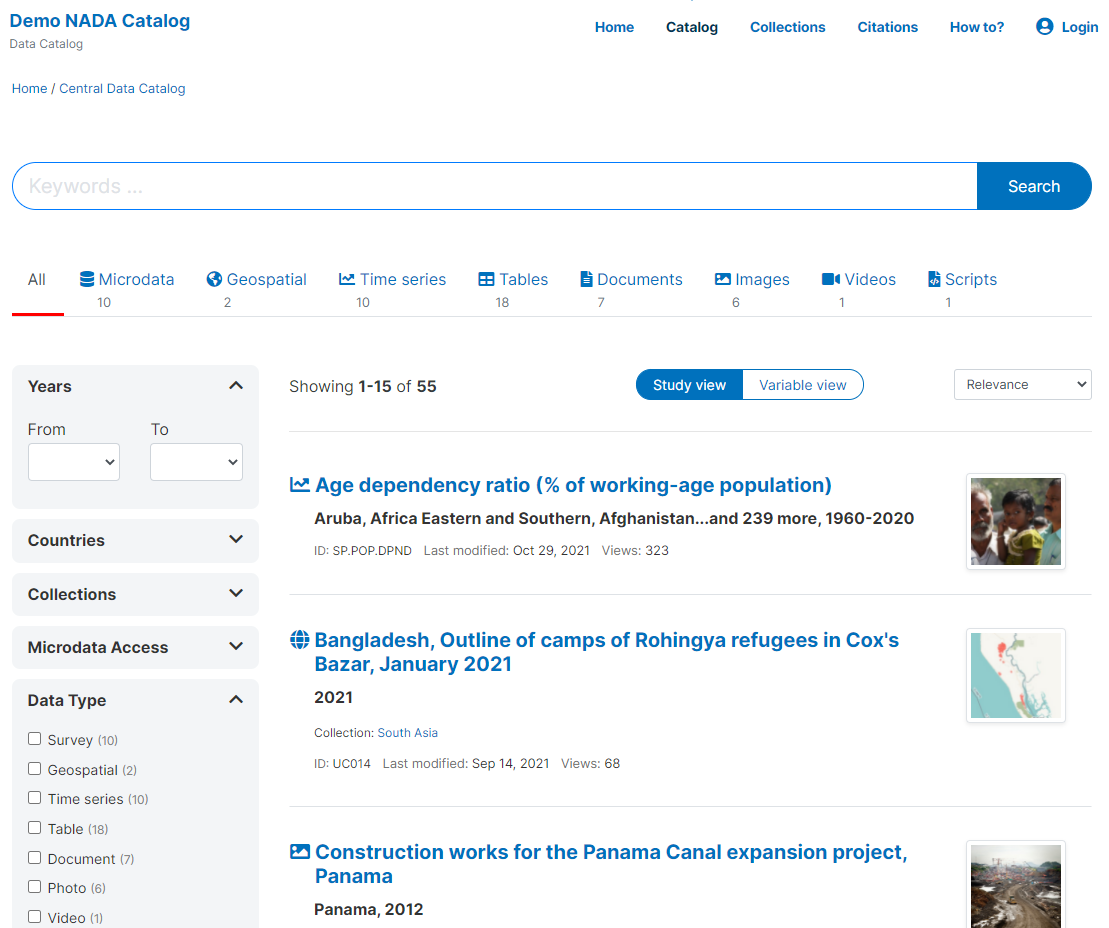
We make a distinction between the following data types, as specific metadata standards and tools are used for their documentation, packaging, and mode of dissemination:
Microdata: Microdata are the unit-level data on a population of individuals, households, dwellings, facilities, establishments, or other. They can be generated from surveys, censuses, administrative recording systems, or sensors.
Statistical tables: Statistical tables are summary (aggregated) statistical information provided in the form of cross-tabulations, e.g., in statistics yearbooks or census reports. They will often be a derived product of microdata.
Indicators and time series: Indicators are summary (or aggregated) measures derived from observed facts (often from microdata). When repeated over time at a regular frequency, the indicators form a time series.
Geographic datasets and geographic data services: Geographic (or geospatial) data identify and depict geographic locations, boundaries, and characteristics of the surface of the earth. They can be provided in the form of datasets or data services (web applications).
Text: Text is data. Using natural language processing (NLP) techniques, text can be converted into structured information. NLP tools and models like named entity recognition, topic modeling, word embeddings, sentiment analysis, text summarization, and others make it possible to extract quantitative information from unstructured textual input.
Images: This refers to photos or images available in electronic format. Images can be processed using machine learning algorithms (for purposes of classification or other). Note that satellite or remote sensing imagery are considered here as geographic (raster) data, not as images.
Videos.
Scripts: Although they are not data per se, we also consider the programs and scripts used to edit, transform, tabulate, analyze and visualize data as resources that need to be documented, catalogued, and disseminated in data catalogs.
# Metadata standards and schemas
The usability and discoverability of data depends heavily on the quality of the underlying metadata. For that reason, NADA relies on and requires structured metadata. Data documentation (metadata) is critical to both data users and data producers.
Metadata help the data user:
Find and access data of interest. Without labels, abstracts, keywords, and other important metadata element it might be difficult for a researcher to locate specific datasets and variables.
Assess the quality of the data. To know whether data are useful for a specific purpose, users may need information not only about the content of the dataset, but also about the process that led to the production of the data.
Understand and use the data. Without proper documentation, the risk is high that secondary users may misunderstand and misuse the data.
The availability of good metadata also has significant benefits for data producers. It:
Ensures transparency, auditability, and credibility of the data production process.
Supports the harmonization and integration of data across sources and types and over time.
Increases the visibility and discoverability of data.
Ensures efficiency in data dissemination. Publishing detailed metadata reduces the need to answer users' queries.
Preserves institutional memory.
To serve the purposes of improving transparency, auditability, visibility, discoverability, and usability of data, metadata must be rich and structured. Structuring metadata means organizing and storing the metadata according to standards and schemas (metadata "standards" are "schemas"; we consider that a schema is a standard when its development and maintenance is governed by a recognized organization). The use of metadata standards and schemas provides multiple advantages: they foster completeness of the documentation, they enable the inter-operability of software and systems and facilitate metadata exchange, they contribute to improved data discoverability, and they facilitate assessments of comparability and consistency across datasets.
We need a specific metadata standard for each relevant type of data. Some standards have already been developed and published by the academia, by the ISO organization, by public agencies, or by the private sector. The following standards and schemas are used (in and adapted form) by NADA:
Standards
For microdata: DDI Codebook (opens new window) by the Data Documentation Initiative (DDI) Alliance
For geospatial datasets: ISO 19110 (opens new window)/19115 (opens new window)/19119 (opens new window) and their XML representation ISO19139 (opens new window)
For documents: Dublin Core (opens new window) Metadata Initiative (DCMI) with some elements from the MARC21 (opens new window) (format for bibliographic data by the US Library of Congress) and BibTex as a structure for bibliographic citations.
For images: International Press Telecommunications Council (IPTC (opens new window)) and Dublin Core.
For videos: Dublin Core and the videoObject (opens new window) schema of schema.org (opens new window).
Schemas
For time series and indicators: A schema was developed to document time series and the databases they belong to.
For statistical tables: A schema was developed by reviewing a diverse set of statistical tables (from statistical yearbooks, census publications, and others) and deriving a set of metadata elements that accommodates the structure and components of these tables.
For scripts (data transformation/analytics). Reproducibility, replicability and full auditability of data and analytics cannot be achieved without publishing scripts. A schema was developed to document research and analytics projects and the related scripts.
For purpose of Search Engine Optimization, NADA also maps these schemas to the DCAT metadata schema.
A Guide on Metadata Standards and Schemas has been produced, which provides detailed information on the structure and content of these schemas, and on their adaptation for use in NADA. The schemas are also described in their API documentation available at https://ihsn.github.io/nada-api-redoc/catalog-admin/# (opens new window)
# Acknowledgments
NADA is an open-source cataloguing application developed and maintained by a team at the World Bank Development Data Group. The development of the application has been supported by funding from the World Bank administrative budget and financial contributions by multiple partners to various projects:
The World Bank Development Grant Facility (DGF) financed much of the development and maintenance work from 2006 to 2015, as an activity of the International Household Survey Network (IHSN (opens new window)).
A grant from the Foreign, Commonwealth & Development Office (FCDO) of the United Kingdom (formerly DFID), provided through the World Bank Trust Fund for Statistical Capacity Building (TFSCB) to support the IHSN activities from 2016 to 2020.
A grant from the Omydiar Network (India) (2020-2021), which supported the implementation of NADA-based data cataloguing tools for publishing the India Census data. This contribution allowed us to develop an API-based data and metadata management system and a R package for automating tasks of catalog maintenance.
A grant from the Foreign, Commonwealth & Development Office (FCDO) that supports the development of a dissemination platform for data related to fragility, conflict, and violence (FCV), from 2019 to 2022. This grant has supported the development of multiple new features of the application.
A grant from the Knowledge for Change Program (KCP) (2019-2021), which allowed us to test natural language processing approaches to improve data discoverability, which will eb implemented into NADA.
The development of NADA has also benefited from many in kind contributions, typically in the form of feedback and suggestions, provided by multiple organizations that use NADA, including the Food and Agriculture Organization (FAO), DataFirst at the University of Cape Town, the International Labour Organization (ILO), the Pacific Community (SPC), the United Nations High Commission for Refugees (UNHCR), UNICEF, and the World Health Organization (WHO).
NADA and the related tools (R package NADAR and Python library PyNADA) are built on multiple open-source software and on metadata standards, in particular:
Software: PHP, MongoDB, SOLR, R, Python
Metadata standards: Data Documentation Initiative (DDI), Dublin Core, IPTC, ISO19139
The NADA demo catalog includes visualizations that make use of eCharts by Baidu, Leaflet, and Open Street Map (OSM).
The production of NADA and its documentation is led by a team at the World Bank Development Data Group. Mehmood Asghar and Olivier Dupriez coordinate the development of NADA. Tefera Bekele, Cathrine Machingauta, Kamwoo Lee, Matthew Welch contributed to the development, testing, and documentation of the application.